Vibe Coding一个Python版本的pdf2svg
我的博客里面的插图很多都是用Tikz写的,然后编译成PDF再转换为SVG,具体的流程见之前的文章。
这里面关键的一步就是如何将PDF转换为SVG。
我能找到的唯一一个工具就是pdf2svg,但是它非常简单,而且并不完全符合我的需要。
例如,我发现直接生成的SVG图片太小了,需要放大到1.5倍,里面的字母才会和正文中的字母大小基本一致。这就必须要修改源代码才能解决:
1 | diff --git a/pdf2svg.c b/pdf2svg.c |
最近看到了这篇文章,作者使用Vala重写了pdf2svg工具。于是突然想到,我完全可以重写一个Python版本的pdf2svg。之前也有过类似的念头,不过嫌麻烦就放弃了。
正好最近DeepSeek-V4-Pro模型新发布且大降价,我就使用把它接入Claude Code来完成这次的重写任务。
当然,也是顺带测试一下DeepSeek的新模型。
结果非常成功,一次对话就完成了重写,后面添加了几个功能(将缩放大小、背景颜色作为参数输入,允许更宽泛的页码范围参数),都是一次性就完成了。
具体代码见pdf2svg.py。
期间的几点发现:
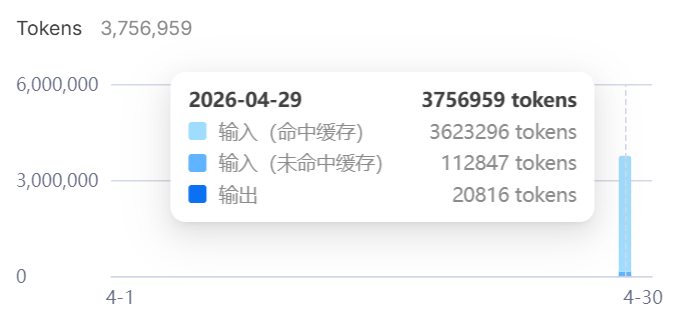
- 刚开始的时候,我发现Claude Code计算的tokens数基本是DeepSeek实际用量的两倍,如图所示:



其中25号使用的都是flash模型,29号使用的都是pro模型。
最初我没想明白,后来刷到了X上的推文,发现是使用中文造成的:
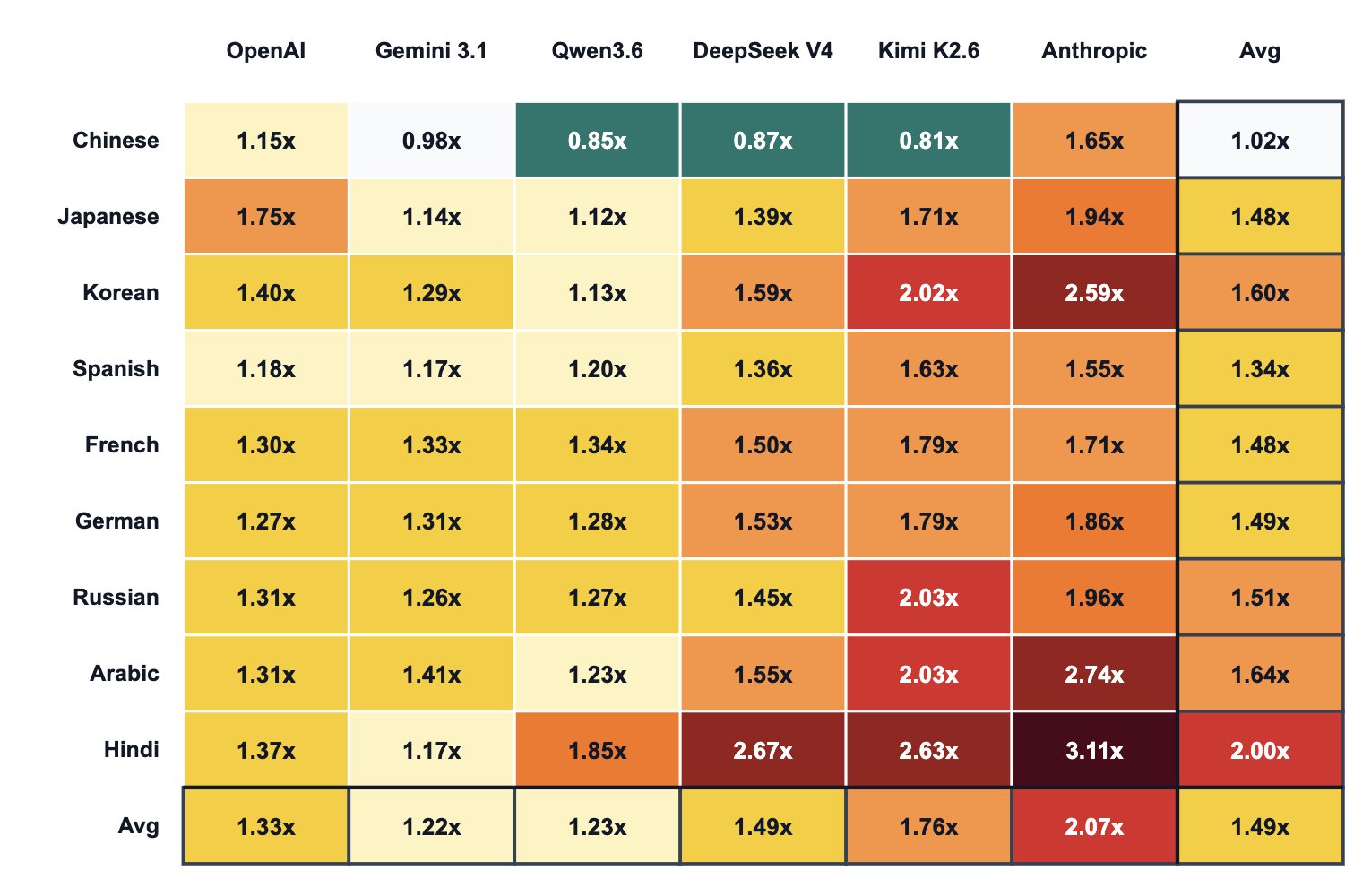
上图中的表格是将同一篇文章翻译成不用的语言之后使用不同模型进行处理,和OpenAI的模型直接处理原始英文文本的tokens数量的对比,作者将其成为「non-English tax」。
横向对比会发现,同样是处理中文文本,Anthropic的模型的tokens用量基本就是DeepSeek V4的两倍。这和前面的观察是相符的。
-
我参考这篇文章设置了全局记忆,但是不知道为什么,实际并没有自动生效。最后是我手动命令它「读取global memory」才起了作用。
-
由于编程的上下文大都是英文,所以最终Claude Code计算的tokens总用量和DeepSeek实际的用量差的没那么多了。最终花费不到6毛钱,其中将近97%的缓存命中率立了大功。